唱歌時,是否曾感覺到自己無法掌控音準,甚至被旁邊人的聲音拉走?這與大腦對聲音的控制機制有關。臺灣師範大學英語系教授甯俐馨的一份研究,揭示了人類對聲音干擾的反應模式,並提出切換型、反對型、跟隨型三種不同反應類型,這項研究也為語音學習、語言治療領域,提供了新的思考方向。
人類大腦在處理聲音時,有兩個主要運作機制,分別為前饋(Feedforward)與反饋(Feed back)。若以開車來比喻,前饋機制如同「油門」,大腦會根據過去累積的經驗,快速、準確地發出語音;反饋機制則像是「剎車」,當人們發現自己音調偏離時,它會進行即時調整。這兩個機制在大腦中協同運作,確保我們的發音與預期相符,如同汽車油門與煞車要妥善控制,也才能安全上路。
這項研究收集了36位中文使用者數據,每位參與者依次發出單一母音「/a/」,每次維持3秒鐘,休息兩秒鐘後,再發出下一個母音,總共30次。而在發音過程中,參與者會透過耳機聽到自己的聲音,但在這3秒鐘內,也會聽到一個比原本聲音高或低,且長達200毫秒的人工音頻,過程中參與者可能會被影響,研究人員再透過潛在類別分析,最後一共分類出三種主要的反應模式。
其中,「切換型」佔57%,受試者在試驗中交替出現「反對」和「跟隨」反應。這類人群的反應具有高度可塑性,時而跟隨干擾聲音,時而修正音調,顯示出他們的大腦能夠靈活適應不同情境,如同開車時油門、煞車視情況亂踩。
「反對型」則佔28%,這類人主要表現為即時校正音調的「反對」反應,他們的大腦對音調變化具有高度堅固性,能夠迅速回應錯誤並保持音準不變,能夠及時停損;「跟隨型」佔15%,這類受試者容易被環境聲音帶走,表現出「跟隨」反應,當他們聽到音調偏移時,會隨之改變自己的音調,顯示出大腦對聲音訊號處理較為鬆散,別人走音自己也跟著走音。
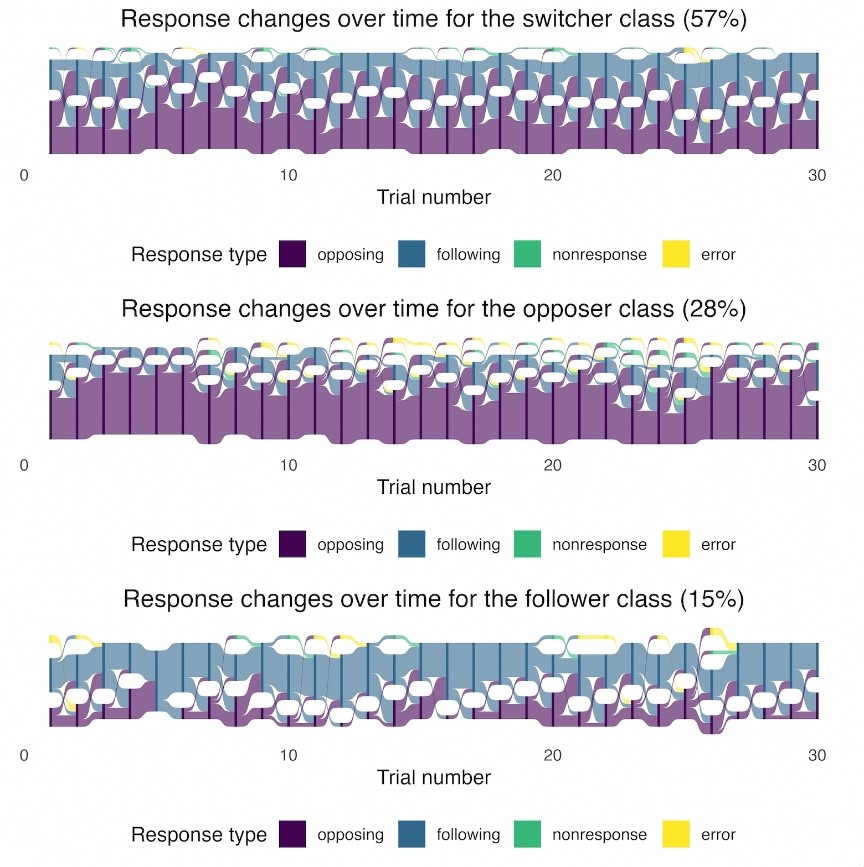
圖說:這項研究收集了36位中文使用者數據,每位參與者依次發出單一母音「/a/」,每次維持3秒鐘,休息兩秒鐘後,再發出下一個母音,總共30次。
過往研究多認為,發音控制良好的人,例如歌手或聲樂家,能更精準地抵抗環境中的音調干擾,當偵測到錯誤音頻,就會即時踩下煞車。但長期研究語音學、發音語音學和心理語言學的甯俐馨,則挑戰了這一項觀點,透過研究分析,提出一個更複雜的反應模式—「跟隨型」、「反對型」和「切換型」,三者呈現了人類在音調干擾下的多樣反應。而當音高變化方向可預測時,跟隨反應的比例會顯著上升,顯示「預測性」在語言控制中的重要性。
這項研究也發現,若將參與時間拉長,參與者的反應也會出現變化。甯俐馨將實驗分為初始、中間、最終三個階段,參與者在一開始傾向於使用一致的反應機制,隨著時間推移,反應模式會在「反對」與「跟隨」之間進行切換,而到實驗後期,他們則會趨於穩定,選擇固定的反應方式,這現象也為語言學習的可塑性,提供了新的視角。
這份研究從動作科學、語音科學,再到語言學習,屬於跨領域合作。甯俐馨坦言,過程中也經歷不小的挑戰,尤其臺灣在音訊工程領域的專業人才相對稀缺,光找合作對象就花上一、二年的時間,後來終於找到香港都會大學專任高級講師許德彰博士,他不但具有音樂背景,又會寫程式且與製作電子音樂,透過與專業背景不同的合作夥伴協同工作,研究團隊終於克服技術瓶頸,並成功完成這份研究。
談及研究應用與未來方向,甯俐馨表示,這項研究結果可用於語言學習與語言治療,特別是針對在聲調控制上有困難的學習者。而在語言學習方面,這項研究揭示了不同學習者對語音的反應模式,並根據其反應類型,有望針對高度可塑性與反應固著的的學習者,量身定制學習方法,也能幫助提高語音控制能力,為語言障礙患者帶來新的治療方向。
臺師大校內也設有「神經語言學實驗室」,甯俐馨說,目前研究多聚焦在行為實驗,未來希望將這項研究與腦科學結合,觀察大腦如何控制人類在發音時的反應,進一步驗證行為實驗所提出的觀點,提供更精確的科學數據。(採訪撰文 | 由本校公共事務中心提供)。
原文出處:Ning, L. H.(2022).Identifying distinct latent classes of pitch-shift response consistency: Evidence from manipulating the predictability of shift direction. Frontiers in Psychology, 13, https://doi.org/10.3389/fpsyg.2022.1058080

