侯文娟 助理教授 | 資訊工程學系
侯文娟博士畢業於國立臺灣大學資訊工程研究所,目前任教於國立臺灣師範大學資訊工程學系。侯教授的研究領域為生醫文件探勘、自然語言文件之語意分析,及其他自然語言處理技術相關議題。近年來侯教授的研究主題包括藥物─藥物交互作用之研究、生物事件擷取與分類技術及遷移學習之研究、基因與疾病關係、藥物與疾病關係擷取之研究,及中文部落格情緒分析之研究。
【本篇報導由資訊工程學系 侯文娟博士研究團隊提供】
近年來人工智慧之深度學習模式深受注目,我們的研究即以此技術應用於生物事件辨識與擷取,並以遷移學習的方法得以減少語料庫建置的需求。
生物文件中複雜的生物過程如果以結構性的方式表達(例如:調節網路),往往比文字描述更為清楚,故自動化地從生物文件中產生調節網路,並標註生物事件及事件-事件或事件-實體等關係,為生物學家所重視的議題,是以我們的研究目標為發展表示調節網路所需的生物事件及關係擷取系統。此外,機器學習方法需大量語料庫,此語料庫常是人工建置,非常耗時耗力,有鑑於此,在這個研究當中我們提出兩種學習方法,從兩個獨立不同的語料庫建置共同資料集,並以深度學習模組發展多重領域之事件及關係擷取系統,目的在於可使用單一系統處理多重領域問題,如此可以節省人工建置語料庫所需的大量時間與人力。
系統生物學可辨認生物系統不同部分之交互作用結果,此結果稱為事件,事件與實體、事件與事件間可形成關係。事件擷取及標註是近年生物家重視的問題,其中從生物文件中產生基因調節網路之議題則深受研究者重視,主要是複雜的生物過程若以結構性方式表達,會比用文字描述更清楚。然而真實世界中具有大量的生醫相關文件,研究者不可能逐篇仔細地閱讀所有的文章,因此文件探勘常常使用機器學習方法,但通常供機器學習方法學習的語料庫往往是人工產生的。
傳統上,以機器學習方法建立的訓練模組和測試領域是相同領域,如果將領域A的訓練模組用於領域B,往往預測效能會大幅降低。例如圖一,訓練時是老鼠的基因資料,測試時用以辨認老鼠基因,正確率可達84.1%,但是如果訓練的基因資料只能取得果蠅資料時,這樣以果蠅資料建立的模組用在辨認老鼠基因,正確率可能就會大幅下降(如圖所示為58.1%)。
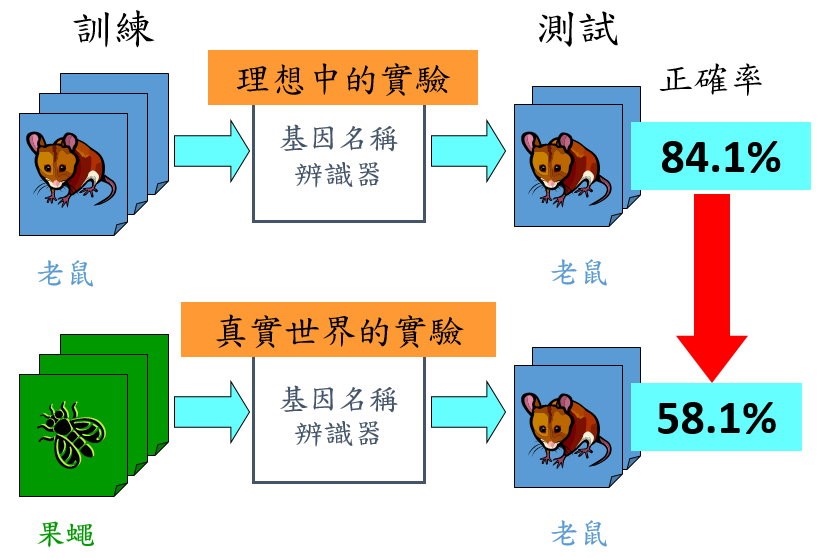
圖一:訓練資料與測試資料相同/相異,產生的效能不相同
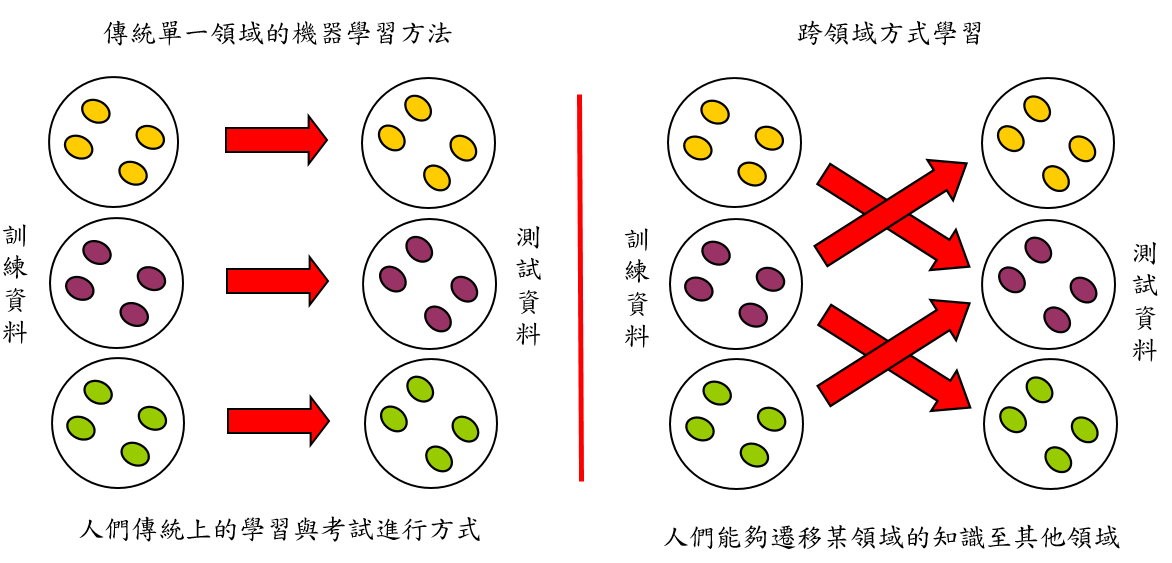
圖二:單一領域學習方式與跨領域學習方式之圖示
如前所述,因為生醫文件內容複雜,使用自然語言處理及機器學習方法擷取生物事件具有相當的挑戰性,為了自動化標註及擷取事件,常使用機器學習方法。然而,事件擷取與標註方法及相關資源的研究至目前為止幾乎都集中在單一領域。本研究提出使用遷移學習及結構對應學習方法,從兩個不同領域產生共同資料集,並建置深度學習事件擷取系統,我們的研究提出的步驟為(1)從兩個獨立的事件擷取任務產生資料集,(2)使用分類模組從資料集學習特徵樣式。此法重要貢獻為(1)自動建置共同資料集,節省人工建置代價,(2)訓練和測試集可為不同領域。
總述而論,考量人工標註文件耗時耗力,本研究提出此學習方法,從兩個獨立任務建立資料集,以深度學習模組處理事件及關係擷取問題。

侯文娟博士畢業於國立臺灣大學資訊工程研究所,目前任教於國立臺灣師範大學資訊工程學系。侯教授的研究領域為生醫文件探勘、自然語言文件之語意分析,及其他自然語言處理技術相關議題。近年來侯教授的研究主題包括藥物─藥物交互作用之研究、生物事件擷取與分類技術及遷移學習之研究、基因與疾病關係、藥物與疾病關係擷取之研究,及中文部落格情緒分析之研究。







